
Iterative Methods for the Computation of the Perron Vector of Adjacency Matrices †


1
Department of Mathematics and Computer Science, University of Cagliari, Via Ospedale 72, 09124 Cagliari, Italy
2
Department of Mathematical Sciences, Kent State University, Kent, OH 44242, USA
*
Author to whom correspondence should be addressed.
†
Dedicated to Paul Van Dooren on the occasion of his 70th birthday.
Mathematics 2021, 9(13), 1522; https://doi.org/10.3390/math9131522
Submission received: 6 May 2021
/
Revised: 18 June 2021
/
Accepted: 23 June 2021
/
Published: 29 June 2021
(This article belongs to the Special Issue Numerical Linear Algebra and the Applications)
Abstract
:The power method is commonly applied to compute the Perron vector of large adjacency matrices. Blondel et al. [SIAM Rev. 46, 2004] investigated its performance when the adjacency matrix has multiple eigenvalues of the same magnitude. It is well known that the Lanczos method typically requires fewer iterations than the power method to determine eigenvectors with the desired accuracy. However, the Lanczos method demands more computer storage, which may make it impractical to apply to very large problems. The present paper adapts the analysis by Blondel et al. to the Lanczos and restarted Lanczos methods. The restarted methods are found to yield fast convergence and to require less computer storage than the Lanczos method. Computed examples illustrate the theory presented. Applications of the Arnoldi method are also discussed.
1. Introduction
Networks arise in many areas, such as social media, transportation, and chemistry; see [1,2] for many examples. Networks can be represented by graphs that are made up of a set of vertices or nodes and a set of edges , connecting the nodes. Two distinct nodes, and , are said to be adjacent if there is an edge between them. The analysis of graphs by mathematical and computational methods can provide valuable information about the networks they model and is receiving considerable attention.
This paper considers networks that can be represented by simple unweighted graphs, that is, no edge starts and ends at the same node, and there is at most one edge between each pair of distinct nodes. Extension to weighted simple graphs, in which each edge has a positive weight, is straightforward. A graph is said to be undirected if every edge is a “two-way street”; a graph with at least one edge that is a “one-way street” is said to be directed. A directed edge pointing from vertex to vertex can be identified with the ordered pair ; for an undirected edge, this pair is not ordered. A walk of length k in a graph is a sequence of vertices and a sequence of k edges , not necessarily distinct, such that points from to in a directed graph, or connects to in an undirected graph, for . A path is a walk in which all the nodes are distinct.
An unweighted simple graph with n nodes can be represented by its adjacency matrix , where when there is an edge from vertex to vertex ; otherwise, . In particular, for all i. Undirected graphs are associated with symmetric adjacency matrices, while the adjacency matrix for a directed graph is non-symmetric. Typically, the number of edges, m, is much smaller than . This makes the adjacency matrix A sparse. An undirected graph is said to be connected if there is a path connecting each pair of nodes. A directed graph is referred to as strongly connected if there is a directed path from to and vice versa for every pair of distinct nodes. The adjacency matrix A associated with an undirected graph is irreducible if and only if is connected. Similarly, the adjacency matrix A associated with a directed graph is irreducible if and only if is strongly connected.
A problem of considerable interest in network analysis is the determination of the most important vertices of a network. The notion of centrality can be used to identify these vertices. There are many centrality measures available, including degree centrality [1,2], betweenness centrality [3], hub-and-authority centrality [4], and eigenvector centrality [5].
We are interested in investigating the performance of iterative methods for determining the eigenvector centrality of vertices belonging to certain structured graphs with many nodes n. The eigenvector centrality was introduced by Bonacich for quantifying the influence a node has in a network [5], beyond its nearest neighbors, in terms of spectral properties of the associated adjacency matrix. According to the Perron–Frobenius theorem, the largest eigenvalue, , which is known as the Perron root, of a nonnegative irreducible matrix A, is unique and has a unique eigenvector (up to scaling) with positive components . This vector is commonly referred to as the Perron vector of A; see, for example, Meyer ([6] Section 8.3). For notational simplicity, we may assume that is scaled so that . Here and throughout this paper, denotes the Euclidean vector norm. The eigenvector centrality of the vertex is given by the entry of the Perron vector of the adjacency matrix A. A vertex is considered a central, that is, important, vertex of the graph if is the largest entry of . This centrality measure also takes into account the centralities of those nodes to which is connected [7].
Blondel et al. [8] investigated the performance of the power method when applied to determining the Perron vector of a matrix of the form
where is the adjacency matrix for a graph with n nodes, and the superscript T denotes transposition. M can be interpreted as the adjacency matrix of a bipartite graph containing vertices partitioned into two disjoint vertex subsets, whose connections are described by A and occur only across, but not within, the two groups.
There are numerous methods for partitioning the vertex set of a bipartite graph so that its adjacency matrix is of the form (1); see [2,9,10] and references therein. The Perron vector of the matrix (1) is used to determine the hub-and-authority centralities for the vertices of [2,4] and its components give similarity scores between graph nodes. These scores were introduced by Blondel et al. [8]. There are several applications of similarity scores. These applications lead to the construction of a self-similarity matrix associated with a graph, which measures how vertices are similar to each other [8]; see [11] for an application in archaeology of the similarity matrix associated with a bipartite graph and for an algorithm for solving the seriation problem. The latter is a fundamental ordering problem that aims at finding the best enumeration order of a set of units so that in the resulting sequence, elements having higher similarity are placed close to each other.
Given an initial vector with positive entries, the power method applied to the matrix M generates the sequence of vectors
When applied to a real square matrix with a single largest eigenvalue of maximal magnitude, the power method is known to determine a sequence of vectors that converge to the span of the eigenvector associated with this eigenvalue for almost all initial vectors; see, for example, Saad ([12] Section 4.1). The following result, which highlights the property of the adjacency matrix of a bipartite graph of having a spectrum symmetric with respect to the origin ([13] Theorem 3.14), shows why the application of the power method to the matrix (1) is not straightforward.
Proposition 1.
Proof.
Partition the Perron vector of the matrix M defined by (1), where , . Let denote the Perron root of M. Then, implies that
Thus, the negative Perron root is also an eigenvalue of M. □
The presence of more than one eigenvalue of the largest magnitude of M suggests that the sequence of vectors, , might not converge to the Perron vector. Indeed, Blondel et al. [8] show that both the limits
exist, but they might not be the same. The limits depend on the initial vector for the power iteration and none of the limits might be the Perron vector for M. Throughout this paper, denotes the vector with all entries 1 of a suitable dimension. Blondel at al. ([8] Theorem 2) show that when , the limit on the left-hand side of (3) is the Perron vector for M.
An advantage of the power method, when compared to other methods for computing the Perron vector of a matrix with only nonnegative entries, is that only two vectors, and , have to be stored simultaneously during the computations. The low storage requirement may be important for very large matrices; however, convergence of the power method can also be very slow when there is only one eigenvalue of the largest magnitude. The rate of convergence decreases with the distance between the Perron root and the magnitude of the second largest eigenvalue in modulus; see, for example, ([12] Section 4.1). It is therefore interesting to investigate the convergence properties of methods that converge faster, such as the Lanczos or restarted Lanczos methods, when applied to matrices of the form (1) and generalizations thereof. It is the purpose of the present paper to study the convergence of the Lanczos and restarted Lanczos methods when applied to the computation of the Perron vector of matrices of the form (1) and some generalizations. Our analysis is based on results by Blondel et al. [8]. We also discuss the computation of the Perron vector of structured matrices, somewhat related to the matrix M, and by application of the Arnoldi method to the submatrix A in (1). These particular matrices represent graphs with a chained structure that refine the notion of bipartivity [14].
This paper is organized as follows: Section 2 introduces undirected chained graphs. The adjacency matrix for this kind of graph has a staircase structure, which generalizes the structure (1). Chained graphs have been shown to be bipartite in [14], which implies that the eigenvalues of their associated adjacency matrices appear in ± pairs. Section 3 studies the performance of the Lanczos and restarted Lanczos methods when applied to computing the Perron vector for these and other symmetric adjacency matrices. The Arnoldi method and its application to estimating the Perron vector for a symmetric matrix considered by Blondel et al. [8] are described in Section 4. A few computed examples are presented in Section 5, and Section 6 contains concluding remarks.
2. Undirected Chained Graphs
This section describes ℓ-chained undirected graphs and the structure of their adjacency matrices. These graphs, which are particular bipartite graphs, were introduced in [14] and are defined as follows.
Definition 1.
An undirected graph is said to be -chainedwith initial vertex if the set of vertices can be subdivided into disjoint non-empty subsets
such that , and all vertices in the set , are adjacent only to vertices in the sets or for , where the chain length is the largest number of vertex subsets with this property. Moreover, the vertices in and are adjacent only to vertices in and , respectively. Vertex sets with consecutive indices are said to be adjacent.
Consider an undirected ℓ-chained graph with vertex set partitioning . Let be the cardinality of the vertex subset for . Thus, the graph has nodes. Order the vertices of so that the vertices in precede those in for , and define the matrix that describes the connections between the vertices in and the vertices in for . Then, the adjacency matrix , associated with , has the staircase structure
Theorem 1
([14]). An ℓ-chained graph is bipartite. Conversely, if a graph is bipartite, then the graph is ℓ-chained for some .
From Theorem 1 it follows that, for a suitable permutation matrix , the adjacency matrix (4) can be permuted to the form
with , where
Here, denotes the integer part of . The structure (5) is the same as (1). It follows from Proposition 1 that the adjacency matrix for an ℓ-chained undirected graph has pairs of eigenvalues of the opposite sign, which include the Perron root.
Example 1.
Consider the 3-chained graph with adjacency matrix
where . Then
Introduce the permutation matrix
where is the identity matrix. Then, the matrix is defined by
3. The Lanczos and Restarted Lanczos Methods
This section discusses the application of the Lanczos and restarted Lanczos methods to the computation of the Perron vector of an undirected connected graph. We first consider the Lanczos method and subsequently turn to restarted variants.
The Lanczos method reduces a large symmetric matrix to a usually much smaller symmetric tridiagonal matrix by computing an orthogonal projection onto a Krylov subspace of fairly low dimension. It is a commonly used method for determining approximations of a few large eigenvalues and associated eigenvectors of a large symmetric matrix; see, for example, [12] for a discussion of this method.
Consider an undirected connected graph with associated adjacency matrix . Application of steps of the Lanczos method to A with initial vector yields, generically, the Lanczos decomposition
where the columns of the matrix form an orthonormal basis for the Krylov subspace,
with . Throughout this paper, denotes the kth axis vector of the suitable dimension. Moreover,
is a symmetric tridiagonal matrix, the coefficient in (8) is positive, and the vector satisfies and . We tacitly assume that the number of steps k of the Lanczos method is small enough so that the decomposition (8) with the stated properties exists. This is the generic situation.
Let denote the largest eigenvalue of , and let be an associated unit eigenvector. Then, and are commonly referred to as a Ritz value and a Ritz vector, respectively, of A.
Theorem 2.
Consider an undirected connected graph with adjacency matrix . Then, M is symmetric and nonnegative. Let ρ denote the Perron root of M and let be the associated Perron vector. Apply k steps of the Lanczos method to M with initial vector . This produces the decompositions
Let denote the largest eigenvalue of with the associated Perron vector . Then, the Ritz values converge to the Perron root ρ of M and the Ritz vectors converge to as k increases. If the Lanczos method breaks down at iteration ℓ, then is the Perron vector.
Proof.
The eigenvectors of M are stationary points of the Rayleigh quotient
and the eigenvalues of M are the values of at these stationary points. The Perron root is the maximum value of . The largest eigenvalue of is the maximum value of over the k-dimensional Krylov subspace . It follows that .
Blondel et al. ([8] Theorem 2) show that, using the initial vector , the sequence in (2) generated by the power method converges to the Perron vector of M. The unit vector lives in . Clearly,
Since the Krylov subspaces , are nested, it follows that
It is a consequence of the mentioned result by Blondel et al. [8] that the Lanczos method does not break down until the Perron vector has been determined. Assume, to the contrary, that the Lanczos method breaks down at step k. Then, the relation (9) is replaced by
which shows that the range of forms an invariant subspace of M. This implies that the vector , determined by the power method in the next step, lives in the range of . This would imply that the Perron root of M is the Perron root of , and therefore the Lanczos method determines the Perron root and Perron vector.
It follows from (10) that converges to and, due to (11), the sequence converges monotonically to (from below) as j increases. Let be the Perron vector of . Since is an irreducible symmetric tridiagonal matrix, the unit vector is uniquely determined. Then, the associated Ritz vectors converge to the Perron vector of M as j increases. We remark that the Ritz vectors so obtained, , may have small negative entries. This is of no importance, since we are interested in determining the largest component(s) of these vectors. □
The iterations of the Lanczos method applied to M are terminated as soon as two consecutive approximations and of the Perron vector are close enough, that is, as soon as
for some user-specified (small) value of . Note that
Thus, it suffices to choose a k large enough so that
The Lanczos iteration is described by Algorithm 1. The algorithm applies the Lanczos method to a general real symmetric matrix . In Line 14 of the algorithm, the symmetric tridiagonal matrix is augmented by appending a row and a column to obtain the new symmetric tridiagonal matrix .
| Algorithm 1 Determine the Perron vector of the matrix M by the Lanczos method. |
|
The following example compares the results of finding the most important vertices of each vertex subset of an undirected 4-chained graph by the power method and the Lanczos method with initial vector . In this comparison, we terminate the iterations with the power method as soon as two consecutive approximations and of the Perron vector are sufficiently close, that is, as soon as
Example 2.
This example uses the Citeseer Index data set downloaded on June 2007 from the website [16]. The data set consists of a list of papers with some information such as authors, journals, and institutions. We extracted an undirected 4-chained network from this data set. It shows relations between the vertex subsets institutions, authors, papers and journals. The number of vertices that represent institutions, authors, papers and journals are 20, 58, 26 and 21, respectively. The power method and the Lanczos method are applied with the stopping criteria (13) and (12), respectively, with .
Both the power and Lanczos methods identify vertex as the most important university, vertices and as the most important authors, vertex as the most important paper, and vertex as the most important journal. The power method terminates the iterations after step 364, while the Lanczos method stops at step 26. Thus, the Lanczos method requires the evaluation of significantly fewer matrix–vector products with the matrix M than the power method to determine the most important vertices of each vertex subset.
Typically, the Lanczos method yields much faster convergence to the Perron vector of a symmetric nonnegative matrix M than the power method. However, it has the drawback of requiring storage space for the matrix in (9). The need to store the matrix may make it difficult to apply the Lanczos method to compute the Perron vector of very large adjacency matrices. We describe two standard approaches for circumventing this difficulty. They restart the Lanczos iterations in different ways.
- (i)
- Carry out the Lanczos iterations twice: First generate the tridiagonal matrix for a suitably chosen k (see below) and discard the columns of the matrix that are not required by the Lanczos method for determining the next column. Indeed, to compute column for only the columns and are needed. Thus, the storage demand is modest and bounded independently of the number of Lanczos steps k. Having computed the Perron vector for , we have to evaluate the corresponding Ritz vector . This can be done by regenerating the columns of . Thus, we determine these columns by applying the recursion formula of the Lanczos method again and discard the columns as soon as their contribution to the Ritz vector have been evaluated. The inner products that determine the nontrivial entries of do not have to be recomputed. This approach of reducing the storage amount is straightforward, but it doubles the number of matrix–vector product evaluations with M. This method is described by Algorithm 2. The iterations are terminated similarly as in Algorithm 1.
- (ii)
- Restart the Lanczos method, that is, compute an approximation of the Perron vector every k iteration, and use this approximation as a new initial vector when restarting the Lanczos iterations. The vector is used to initialize the very first k Lanczos steps. The method is restarted until the stopping criterion is satisfied. The storage requirement of this restarted Lanczos method is limited to essentially the matrix , independently of the number of iterations that are carried out. However, the rate of convergence of computed approximations of the Perron vector may be slower than for the un-restarted Lanczos method. This method is discussed in Theorem 3 below.
Example 3.
We applied Algorithm 2 to the adjacency matrix of the 4-chained network described in Example 2, with . The stopping criterion was satisfied at step 20. The algorithm determined the same vertices as the standard Lanczos method in Example 2. The main differences between Algorithm 1 and Algorithm 2 are that the latter requires less computer storage, but more matrix–vector product evaluations with M (40 vs. 26). The difference in the number of steps required by Algorithms 1 and 2 depends in part on the different stopping criteria used. In Algorithm 1, the iterations are terminated when two consecutive Ritz vectors are close enough, while Algorithm 2 is terminated when two consecutive Ritz values are sufficiently close.
We turn to computing the Perron vector of M by the restarted Lanczos method described in (ii). This method applies k steps of the Lanczos method to the matrix M with initial vector to determine the decomposition (9), and computes the Perron vector of the symmetric tridiagonal matrix in this decomposition. We denote the Perron root of by . Then, is the Ritz vector of M that best approximates the Perron vector, and is the corresponding Ritz value. The computed Ritz vector may have negative entries, while the Perron vector of M is known to only have strictly positive entries. We therefore set all entries of that are smaller than a small , say , to , and refer to the vector so obtained as .
| Algorithm 2 Determine the Perron vector of the matrix M by applying twice the Lanczos recursions. |
|
The vector is used to determine an improved approximation of the Perron vector of M. Thus, we apply k steps of the Lanczos method to M with initial vector . This gives a decomposition analogous to (9). We compute the Perron vector and the Perron root of the symmetric tridiagonal matrix in this decomposition. Proceeding similarly as described above, we obtain a new approximation of the Perron vector of M. We denote this approximation by . The latter vector is used as an initial vector for k steps of the Lanczos method applied to M, which yields a new approximation, , of the Perron vector and a new approximation of the Perron root of M. This approximate Perron vector is computed, similarly, as . We determine approximate Perron vectors and Perron roots for , until two consecutive Perron vector approximations are sufficiently close, that is, until
for a user-supplied tolerance .
The following result shows that the vectors converge to the Perron vector of M when the number of Lanczos steps, k, used to determine from for , is large enough and the stopping criterion (14) is not applied.
Theorem 3.
Let be the adjacency matrix of an undirected connected graph , and let ρ and denote the Perron root and Perron vector of M, respectively. Apply the restarted Lanczos method described above with initial vector and without the stopping criterion (14). If the number of Lanczos steps between restarts, k, is large enough, then the computed sequence , , of approximations of the Perron vector converges to as i increases. Similarly, the computed sequence for , of approximations of the Perron root ρ, converges to ρ as i increases.
Proof.
Blondel et al. ([8] Theorem 2) show that, given a strictly positive initial vector, the sequence , , in Equation (2) generated by the power method, converges to the Perron vector of M. It follows that Theorem 2 also holds when the initial vector is replaced by any vector with all entries being strictly positive. In particular, Theorem 2 holds for all the initial vectors , , used in the restarted Lanczos method. Let us set .
The Ritz value , determined by the restarted Lanczos method, satisfies
It follows that, unless is a stationary point of the Rayleigh quotient, . According to Theorem 2, the vector can be a stationary point only if it is the Perron vector. Thus, we may assume that .
The vector used in the next restart is not the Ritz vector of M that corresponds to the Rayleigh quotient , because all entries smaller than some tiny in this Ritz vector are set to . This means that the Rayleigh quotient
may be smaller than . We have to choose the number of Lanczos steps between restarts, k, large enough so that is significantly larger than for every i. This secures the convergence of the vectors to the Perron vector of M as i increases. □
Example 4.
We apply the restarted Lanczos method to the same adjacency matrix M as in Example 2 to compute its Perron vector and to identify the most important vertices of the associated graph. We let in (14) and carry out steps of the Lanczos method between restarts. All entries smaller than in the Ritz vectors of M associated with the Perron roots of consecutively generated symmetric tridiagonal matrices are set to δ. For the present example, the restarted Lanczos method requires seven restarts, thus, 70 matrix–vector product evaluations are carried out. The computational load is larger than for Algorithm 1, but the storage requirement of the restarted method is smaller and is independent of the number of restarts necessary.
4. The Arnoldi Method
The Arnoldi method can be applied to compute approximations of a few eigenvalues and associated eigenvectors of a large non-symmetric matrix . We will describe a novel application to the computation of the Perron vector of a large symmetric matrix. A thorough discussion of the Arnoldi method and its properties is provided by Saad ([12] Chapter 6). Here, we only provide a brief outline.
The application of steps of the Arnoldi method applied to a large matrix with initial vector gives, generically, the Arnoldi decomposition
where
is an upper Hessenberg matrix with positive subdiagonal entries, the matrix has orthonormal columns, is a unit vector such that , and is a nonnegative scalar. Each step of the Arnoldi method requires the evaluation of one matrix vector product with A. The decomposition (15) exists, provided that the Arnoldi method, outlined in Algorithm 3, does not break down because of a division by zero. This situation is very rare; we therefore will not dwell on it further.
Let denote the largest eigenvalue of , and let be an associated unit eigenvector. Then, and are the corresponding Ritz value and Ritz vector of A, respectively. The iterations with the Arnoldi method are terminated when two consecutive approximations of the Perron vector are sufficiently close, that is, when
for some user-specified tolerance . Algorithm 3 describes the Arnoldi method with initial vector .
| Algorithm 3 Estimate the Perron vector of matrix A with the Arnoldi method with initial vector . |
|
Blondel et al. consider the computation of the Perron vector of the central block
of the matrix (7), where the matrix may be non-symmetric; see [8] Theorem 6. One approach is to apply the Lanczos method to C. Then, each iteration requires the evaluation of two matrix–vector products with A and two with . We will compare this approach to the application of k steps of the Arnoldi method to A.
The Arnoldi decomposition suggests the approximation , from which we obtain
Let be the largest eigenvalue of and let be the associated Perron vector. Then, the vector provides an approximation of the Perron vector of the matrix . The main advantage of using this approximation, when compared to the application of the Lanczos method to the matrix (16), is that the computation of the approximation (17) only requires the evaluation of k matrix–vector products with A, while the computation of k steps of the Lanczos method to the matrix (16) demands the evaluation of matrix–vector products with A or . For many matrices A, the right-hand side of (17) gives an accurate approximation of the Perron vector for a few Arnoldi steps. We provide an illustration below. However, the use of (17) is not always beneficial as the next example shows.
Example 5.
Let be a Jordan block with the eigenvalue zero. Then, A is an adjacency matrix associated with a simple directed graph. The graph and the matrix are displayed in Figure 1.
The Perron root of A is 0, with Perron vector . When applying the Arnoldi method to A with initial vector , the k-dimensional Krylov subspace is spanned by the first k vectors of
In particular, the Perron vector is not contained in the subspaces for . This implies that one has to carry out n steps with the Arnoldi algorithm to determine an accurate approximation of the Perron vector of A. For the present matrix A, Formula (17) requires n steps of the Arnoldi algorithm applied to A to give an accurate approximation of a Perron vector of (16).
We turn to the spectral factorization of the matrix (16). This matrix is diagonal with eigenvalue 2 of multiplicity . The corresponding eigenvectors form the eigenspace
Example 6.
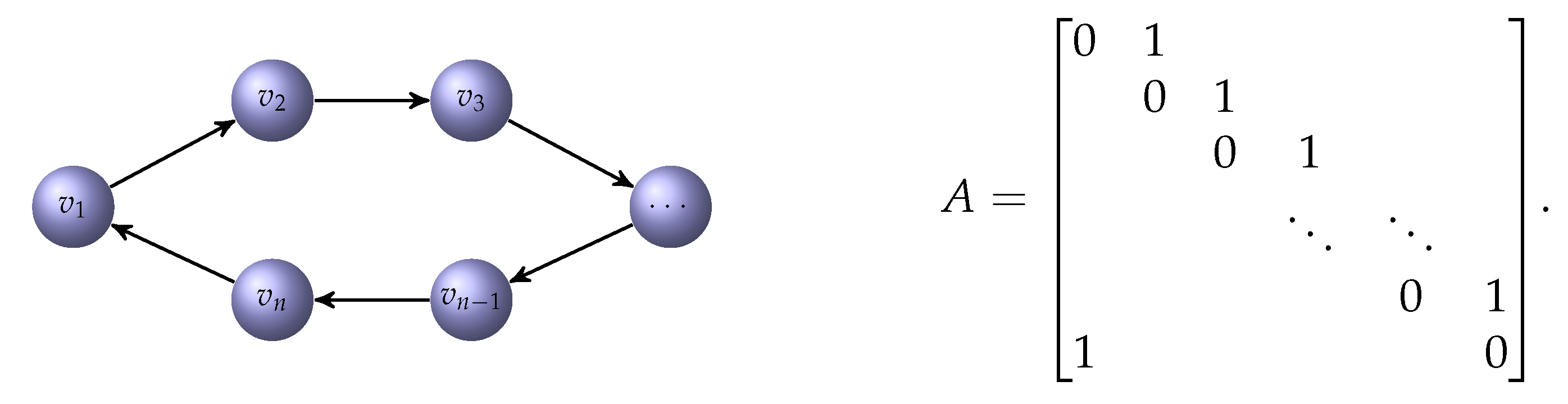
Let represent the adjacency matrix of a directed circular graph. The adjacency matrix and the associated graph are displayed in Figure 2.
In this example, the matrix (16) is diagonal, with Perron root 2 of multiplicity n. In particular, the vector is a Perron vector. Application of one step of the Arnoldi algorithm to the the circulant matrix A with initial vector yields the eigenvector . Thus, the Arnoldi algorithm performs well.
Example 7.
Consider the up-shift matrix on the right-hand side of Figure 1 of order 1000. By adding the perturbation to the entry , we obtain an adjacency matrix A that represents a weighted directed circular graph. Thus, the graph is strongly connected. The associated matrix (16) is diagonal with Perron root 2 with eigenspace . When applying the Arnoldi algorithm to A with initial vector , 1000 steps are required to approximate the Perron vector. In this case, the Arnoldi algorithm performs poorly.
We conclude that the Arnoldi method may not provide useful approximations of the Perron vector of certain non-symmetric adjacency matrices A in a reasonable number of steps. The application of the Arnoldi method to A to compute the Perron vector of the matrix (16) can be competitive with the application of the Lanczos method to the latter matrix, but this is not guaranteed. The closer the adjacency matrix A is to the set of symmetric matrices, the better the Arnoldi method, applied to A, can be expected to perform.
5. Application to Real World Networks
In this section, we apply the iterative methods discussed in this paper to the computation of the Perron vector of large real-world networks, and compare the results obtained.
We start by analyzing a particular 3-chained network and seek to determine the most important vertices of each index subset according to the eigenvector centrality. Some social bookmarking services, such as Delicious, allow their users to put tags on web pages. The relationship between users, web pages and tags, can be represented by a 3-chained network [15]. A data set of Delicious bookmarks, which contains 105,000 bookmarks and 1867 users, is available at the Grouplens web site [17]. We selected data from January 2010 to February 2010 and constructed a 3-chained graph with the three vertex subsets: 456 users, 4253 web pages, and 5962 tags. The total numbers of vertices and edges are 10,671 and 23,550 respectively. The 3-chained network is undirected and represented by the adjacency matrix .
We used the power method, Lanczos iteration, and restarted the Lanczos iteration to estimate the Perron vector of M and to find the most important vertices of each vertex subset. Denote the computed approximations of the Perron vectors of M, obtained by applying the methods mentioned, by , , and , respectively. Let the initial vector be and the tolerance be for all the methods. To estimate the accuracy of the methods, we consider as exact the principal eigenvector of M computed by the built-in function eigs from MATLAB.
Before determining the most important vertices, we first check the accuracy of the approximations of the Perron vector of M computed by the above mentioned methods. We calculate the error, that is, the 2-norm of the difference between each computed approximation of the Perron vector and . The errors of the estimated Perron vectors are for the power method for Lanczos iteration, and for restarted Lanczos iteration. From the errors, we observe that the Ritz vector obtained from the restarted Lanczos method is the most accurate estimator. The Ritz vector from the Lanczos algorithm is moderately accurate, while the vector found by the power method is fairly different from the exact Perron vector .
Let us now look at the performances of each method for finding the most important vertices in the three subsets “users”, “web pages” and “tags”. The results determined by the above methods and the number of iterations required are displayed in Table 1. The most important vertices determined by are displayed in the “Built-in” column. All of the methods identify the vertices , and as the most important user, web page and tag, respectively. The last row, “iterations”, shows that the standard Lanczos method requires 17 matrix–vector product evaluations with A. For the restarted Lanczos, labeled ResLanc, 10 Lanczos steps are performed between each restart. Thus, it requires in this case 30 matrix–vector products. The power method requires the largest number of matrix–vector products. The rate of convergence of the approximation of the Perron vector of M computed by the Lanczos method is faster than those of the other two methods. The Ritz vector of the restarted Lanczos iteration converges more slowly but the computations require less storage space.
To better understand the numerical performance of the methods, we applied them to six undirected networks of different sizes. They are listed, together with their number of nodes, in the first column of Table 2:
- autobahn
- describes the German highway system network; it is available at [18].
- ndyeast
- models the protein interaction network for yeast. The data set was originally included in the Notre Dame Networks Database and is available at [19].
- power
- geom
- is a weighted graph, extracted from the Computational Geometry Database geombib by B. Jones (version 2002) and is available at [19]. The entry of the adjacency matrix is the number of papers coauthored by authors i and j.
- internet
- is a snapshot of the structure of the Internet at the level of autonomous systems, created by Mark Newman from data for 22 July 2006 [21].
Table 2 displays the number of matrix–vector product evaluations carried out by the methods considered to reach convergence. We also report the results obtained for the delicious network for comparison. The label Lanczos2 denotes the results obtained by Algorithm 2, that is, by applying the Lanczos recursion twice to save storage space. In this case, the number of matrix–vector product evaluations is roughly twice the number of iterations required by the standard algorithm (Algorithm 1) if the stopping criterion is adjusted to produce the same accuracy in the approximation of the Perron vector. The restarted Lanczos method (ResLanc) was executed with both ten and five iterations between each restart, so the number of matrix–vector product evaluations is obtained by multiplying the number of iterations by ten and five, respectively. For the other methods, the number of matrix–vector product evaluations coincides with the number of iterations. Table 3 reports the 2-norm errors for each method. The Perron vector returned by the function eigs of MATLAB is considered the exact vector.
We see that the power method requires more iterations than the Lanczos algorithm (Algorithm 1) and delivers approximations of the Perron vector of worse accuracy. Applying the Lanczos method twice by Algorithm 2 saves storage but results in a heavier computational load in order to produce the same accuracy of the computed approximation of the Perron vector. The restarted Lanczos approach has the remarkable feature of requiring the same number of matrix products when it is executed, performing ten and five iterations between consecutive restarts. This means that just a few iterations are sufficient to guarantee convergence. The computer storage requirement is much smaller than for the Lanczos method. The errors in the computed approximations of the Perron vector achieved by the restarted Lanczos method are smaller than the errors obtained with the Lanczos methods (Algorithms 1 and 2). Table 2 indicates that the restarted Lanczos method can be competitive.
6. Conclusions
This paper compares the computational effort and storage requirements of the power method, Lanczos method, and the restarted Lanczos method to determine the Perron vector for a large symmetric adjacency matrix. The application of the Arnoldi iteration is also considered. The power method yields quite a slow convergence, much slower than that of the Lanczos method. However, due to its large storage requirement for large adjacency matrices, the latter method is not practical to use for large-scale networks. Different ways of restarting the Lanczos iterations are considered and found to combine faster convergence than the power method with less storage requirement than the Lanczos method.
Author Contributions
Methodology, A.C., L.R., G.R. and Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
A.C. and G.R. were supported by the INdAM-GNCS research project “Tecniche numeriche per l’analisi delle reti complesse e lo studio dei problemi inversi” and and the Regione Autonoma della Sardegna research project “Algorithms and Models for Imaging Science (AMIS)” [RASSR57257]. L.R. was supported by NSF grant DMS-1720259.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Estrada, E. The Structure of Complex Networks: Theory and Applications; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Newman, M.E.J. Networks: An Introduction; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. J. ACM 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Bonacich, P. Power and centrality: A family of measures. Am. J. Sociol. 1987, 92, 1170–1182. [Google Scholar] [CrossRef]
- Meyer, C.D. Matrix Analysis and Applied Linear Algebra; SIAM: Philadelphia, PA, USA, 2000. [Google Scholar]
- Estrada, E.; Knight, P.A. A First Course in Network Theory; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Blondel, V.D.; Gajardo, A.; Heymans, M.; Senellart, P.; Van Dooren, P. A measure of similarity between graph vertices: Applications to synonym extraction and web searching. SIAM Rev. 2004, 46, 647–666. [Google Scholar] [CrossRef]
- Bondy, J.A.; Murty, U.S.R. Graph Theory with Applications; Macmillan: London, UK, 1976. [Google Scholar]
- Concas, A.; Noschese, S.; Reichel, L.; Rodriguez, G. A spectral method for bipartizing a network and detecting a large anti-community. J. Comput. Appl. Math. 2020, 373, 112306. [Google Scholar] [CrossRef] [Green Version]
- Concas, A.; Fenu, C.; Rodriguez, G. PQser: A Matlab package for spectral seriation. Numer. Algorithms 2019, 80, 879–902. [Google Scholar] [CrossRef] [Green Version]
- Saad, Y. Numerical Methods for Large Eigenvalue Problems, 2nd ed.; SIAM: Philadelphia, PA, USA, 2011. [Google Scholar]
- Bapat, R.B. Graphs and Matrices; Springer: London, UK, 2010. [Google Scholar]
- Concas, A.; Reichel, L.; Rodriguez, G.; Zhang, Y. Chained graphs and some applications. Appl. Netw. Sci. 2021, 6, 39. [Google Scholar] [CrossRef]
- Ikematsu, K.; Murata, T. A fast method for detecting communities from tripartite networks. In Proceedings of the International Conference on Social Informatics, Kyoto, Japan, 25–27 November 2013; Springer: Cham, Switzerland, 2013; pp. 192–205. [Google Scholar]
- CITESEERX, Computer and Information Science Papers. CiteSeer Publications ReserchIndex. Available online: https://citeseerx.ist.psu.edu/index (accessed on 5 May 2021).
- Grouplens. Available online: https://grouplens.org/datasets/hetrec-2011 (accessed on 5 May 2021).
- Biological Networks Data Sets of Newcastle University. Available online: http://www.biological-networks.org/ (accessed on 5 May 2021).
- Batagelj, V.; Mrvar, A. Pajek Data Sets. Available online: http://vlado.fmf.uni-lj.si/pub/networks/data/ (accessed on 5 May 2021).
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Mark Newman’s Web Page. Available online: http://www-personal.umich.edu/~mejn/netdata/ (accessed on 5 May 2021).
- Viswanath, B.; Mislove, A.; Cha, M.; Gummadi, K.P. On the evolution of user interaction in Facebook. In Proceedings of the 2nd ACM Workshop on Online Social Networks (WOSN’09), Barcelona, Spain, 17 August 2009; pp. 37–42. [Google Scholar]
- The Max Plank Institute for Software Systems. Available online: http://socialnetworks.mpi-sws.org/data-wosn2009.html (accessed on 5 May 2021).
Figure 1.
A directed graph and its adjacency matrix A.

Figure 2.
A directed circular graph and its adjacency matrix A.


{kind=link}
{kind=link}
Table 1.
The most important vertices found by the methods discussed for each vertex set, and the number of iterations required by each method.
Table 1.
The most important vertices found by the methods discussed for each vertex set, and the number of iterations required by each method.
| Built-In | Power | Lanczos | ResLanc | |
|---|---|---|---|---|
| “users” | 142 | 142 | 142 | 142 |
| “web pages” | 1368 | 1368 | 1368 | 1368 |
| “tags” | 4796 | 4796 | 4796 | 4796 |
| iterations | 34 | 17 | 3 |
Table 2.
Number of matrix–vector product evaluations required by the methods to reach convergence.
| Network | Size | Power | Lanczos | Lanczos2 | ResLanc | ResLanc |
|---|---|---|---|---|---|---|
| autobahn | 1168 | 163 | 29 | 53 | 60 | 85 |
| ndyeast | 2114 | 1029 | 27 | 53 | 60 | 80 |
| power | 4941 | 49 | 18 | 35 | 30 | 35 |
| geom | 7343 | 19 | 11 | 23 | 20 | 20 |
| delicious | 10,671 | 35 | 17 | 33 | 30 | 30 |
| internet | 22,963 | 35 | 12 | 25 | 30 | 25 |
| 63,731 | 41 | 13 | 27 | 30 | 25 |
Table 3.
Errors produced by the methods with respect to the Perron vector computed by the eigs function of MATLAB.
Table 3.
Errors produced by the methods with respect to the Perron vector computed by the eigs function of MATLAB.
| Network | Size | Power | Lanczos | Lanczos2 | ResLanc | ResLanc |
|---|---|---|---|---|---|---|
| autobahn | 1168 | |||||
| ndyeast | 2114 | |||||
| power | 4941 | |||||
| geom | 7343 | |||||
| delicious | 10,671 | |||||
| internet | 22,963 | |||||
| 63,731 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Concas, A.; Reichel, L.; Rodriguez, G.; Zhang, Y. Iterative Methods for the Computation of the Perron Vector of Adjacency Matrices. Mathematics 2021, 9, 1522. https://doi.org/10.3390/math9131522
AMA Style
Concas A, Reichel L, Rodriguez G, Zhang Y. Iterative Methods for the Computation of the Perron Vector of Adjacency Matrices. Mathematics. 2021; 9(13):1522. https://doi.org/10.3390/math9131522
Chicago/Turabian StyleConcas, Anna, Lothar Reichel, Giuseppe Rodriguez, and Yunzi Zhang. 2021. "Iterative Methods for the Computation of the Perron Vector of Adjacency Matrices" Mathematics 9, no. 13: 1522. https://doi.org/10.3390/math9131522
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.